主题
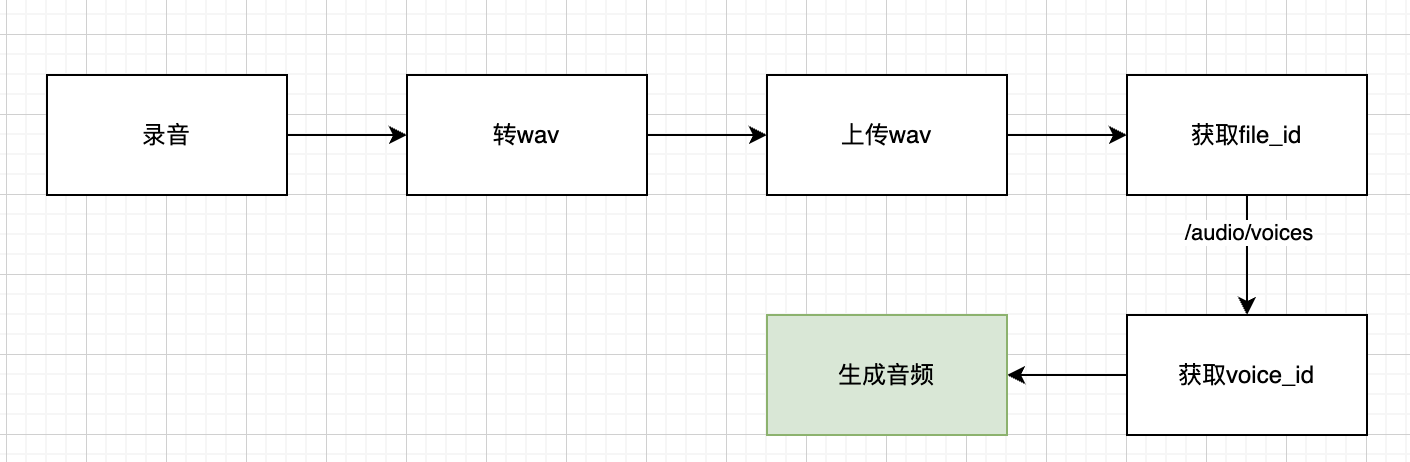
1、录音
2、转wav格式
python
from pydub import AudioSegment
m4a_file = './me.m4a'
wav_file = './me.wav' # 替换为你想要保存的wav文件路径
# 读取m4a文件
audio = AudioSegment.from_file(m4a_file, format="m4a")
# 导出为wav文件
audio.export(wav_file, format="wav")
print(f"文件已成功转换并保存为 {wav_file}")3、上传文件
python
from openai import OpenAI
client = OpenAI(api_key=STEP_API_KEY, base_url="https://api.stepfun.com/v1")
client.files.create(
file=open("./me.wav", "rb"),
purpose="storage"
)输出
json
FileObject(id='file-xxxx', bytes=729132, created_at=1740197078, filename='me.wav', object='file', purpose='storage', status=None, status_details=None)文件id是 file-xxxx
4、复刻音色
python
import requests,json
import base64
data = {
"file_id":"file-xxxx",# 文件id
"model":"step-tts-mini",
"text":"智能阶跃,十倍每一个人的可能",
"sample_text":"今天天气不错"
}
headers = {"content-type":"application/json",
'Authorization':'Bearer '+ STEP_API_KEY}
res = requests.post('https://api.stepfun.com/v1/audio/voices',json.dumps(data),headers=headers)
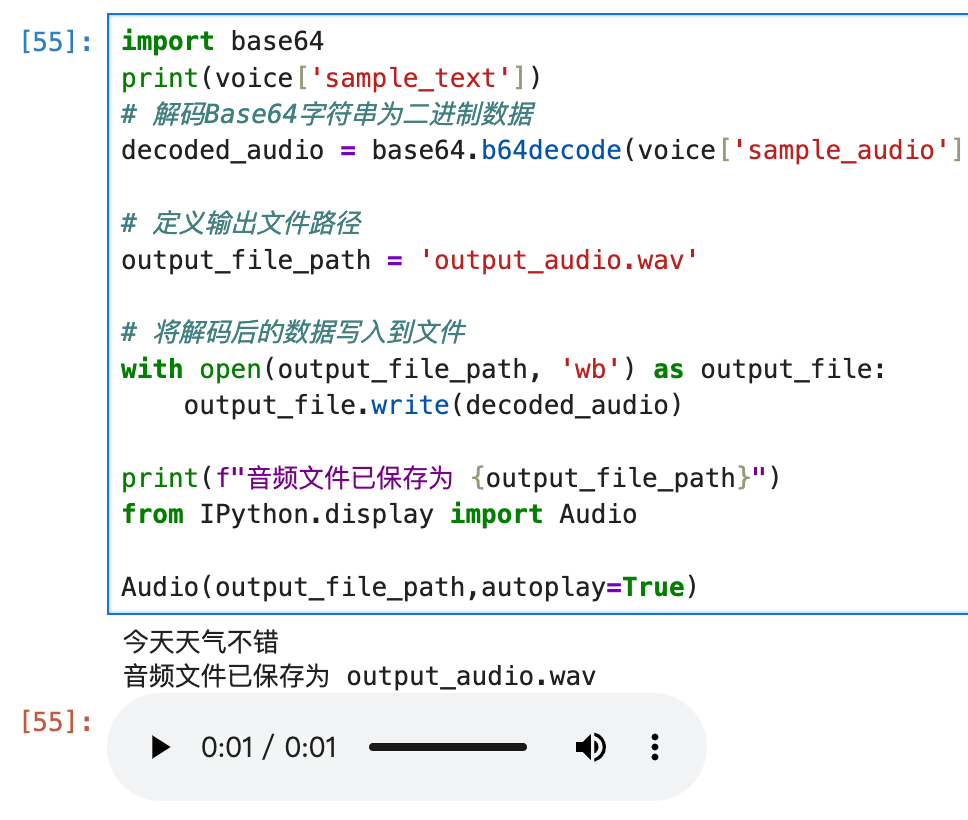
voice = res.json()
print(voice['sample_text'])
# 解码Base64字符串为二进制数据
decoded_audio = base64.b64decode(voice['sample_audio'])
# 定义输出文件路径
output_file_path = 'me_first.wav'
# 将解码后的数据写入到文件
with open(output_file_path, 'wb') as output_file:
output_file.write(decoded_audio)
print(f"音频文件已保存为 {output_file_path}")
from IPython.display import Audio
Audio(output_file_path,autoplay=True)返回值
json
{
'id': 'voice-tone-xxxx',
'object': 'audio.voice',
'duplicated': False,
'sample_text': '今天天气不错',
'sample_audio':'' # base64 音频文件
}接口返回的 voice-tone-xxxx 就是你专属音色id
5、使用专属音色
https://platform.stepfun.com/docs/guide/tts#%E6%94%AF%E6%8C%81%E9%9F%B3%E8%89%B2
python
from pathlib import Path
from openai import OpenAI
import os,time
def get_ts():
now = int(time.time())
timeArray = time.localtime(now)
ts = time.strftime("%Y%m%d%H%M%S", timeArray)
return ts
def tts(text,voice='voice-tone-xxxx'): # 需替换成你自己的
filename =f"{get_ts()}.mp3"
speech_file_me_path = os.path.join(Path.cwd(), filename)
client = OpenAI(
api_key=STEP_API_KEY,
base_url="https://api.stepfun.com/v1"
)
response = client.audio.speech.create(
model="step-tts-mini",
voice=voice,
input=text
)
response.stream_to_file(speech_file_me_path)
return filename来个测试
python
tts_val = '''今天,月之暗面MoonshotAI开源了一个全新的160亿参数规模的MoE大语言模型Moonlight-16B
是一个大规模的混合专家(MoE)模型,参数数量160亿。
官方开源的模型名字是Moonlight-16B-A3B,因为它是160亿参数的大模型,但是每次推理仅激活其中的24亿参数,所以加了一个A3B,A是激活Activation,3B是24亿的参数。
根据官方开源的模型参数,有64个专家和2个共享专家,每次推理的时候每个token会激活其中6个专家。
包含2个版本,
一个是基座版本的Moonlight-16B-A3B,
一个是Moonlight-16B-A3B-Instruct'''
speech_file_path = tts(tts_val)
os.path.join(Path.cwd(),speech_file_path)
# 预览tts
from IPython.display import Audio
Audio(speech_file_path,autoplay=True)